



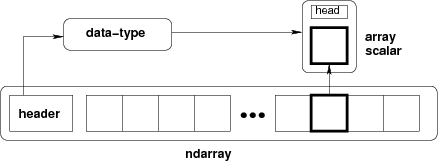
 Conceptual diagram showing the array as a block of memory. source
Conceptual diagram showing the array as a block of memory. source
This article delves into the underlying representation of NumPy arrays in memory. Be forewarned: the topic goes into some detail about NumPy arrays and may be a bit advanced for some.
We will see how a NumPy array can be viewed as a chunk of memory. And, by changing the associated data type, the array can be made to appear as something totally different even though we do not change the underlying data.
A Block of Memory
A NumPy array (ndarray) is nothing but a chunk of memory as shown in the diagram above. This is the simplicity of the NumPy data model as well as its flexibility and power.
The block of memory also has an associated data type -- but, as we'll show below, this can be easily changed. It is like viewing the same data with a different set of lenses.
Each item in the array is of the same data type, i.e. the array is homogenous.
Let's first look at an array of one-byte integers:
>>> x = np.array([1, 2, 3, 4], dtype=np.uint8)
>>> x
array([1, 2, 3, 4], dtype=uint8)
We can print out the bytes in the block of memory:
>>> x.data
<memory at 0x10a09ba00>
>>> bytes(x.data)
b'\x01\x02\x03\x04'
>>> bytes(x.data).hex()
'01020304'
Or simply,
>>> bytes(x).hex()
'01020304'
As an array of int16s
The same array can now be viewed as an array of two-byte integers:
>>> x.view(np.int16)
array([ 513, 1027], dtype=int16)
Voila! The 1 and the 2 combined to make 513 and the 3 and the 4 combined to make 1027. And so we converted an array of 8-bit integers into one of 16-bit integers.
There is a subtle point here -- the bytes are read in little-endian order on my machine which is the equivalent of:
>>> print(0x0201, 0x0403)
513 1027
A bit more about the data
We can get the data's memory location as follows:
>>> hex(x.__array_interface__['data'][0])
'0x7ffc54c7ba30'
The __array_interface__ attribute includes a whole lot of other information:
x.__array_interface__
{'data': (140721730861616, False),
'strides': None,
'descr': [('', '|u1')],
'typestr': '|u1',
'shape': (4,),
'version': 3}
An Example With Structured Arrays and Record Arrays
This time we'll store the (x, y, z) coordinates of a few points in a 3D space. We will do so using 8-bit unsigned ints for each of the coordinates.
# Store (1, 1, 2), (3, 4, 5), and (10, 20, 30)
>>> x = np.array([1, 1, 2, 3, 4, 5, 10, 20, 30], dtype=np.int8)
>>> x
array([ 1, 1, 2, 3, 4, 5, 10, 20, 30], dtype=int8)
And, as before, we can view the raw bytes:
>>> bytes(x).hex()
'0101020304050a141e'
OK. That's great. But how do we get just the x or just the y coordinates?
Well, we can view it as a different data type:
>>> dt = np.dtype({'names': ['x', 'y', 'z'], 'formats': [np.int8] * 3})
>>> points = x.view(dt)
>>> points
array([( 1, 1, 2), ( 3, 4, 5), (10, 20, 30)],
dtype=[('x', 'i1'), ('y', 'i1'), ('z', 'i1')])
Voila! We've converted a list of 8-bit ints into a structured array in which we can now easily separate the x, y, and z coordinates:
>>> points['x']
array([ 1, 3, 10], dtype=int8)
>>> points['y']
array([ 1, 4, 20], dtype=int8)
>>> points['z']
array([ 2, 5, 30], dtype=int8)
We can go a little bit further and convert the structured array into a record array (recarray).
>>> points2 = points.view(np.recarray)
>>> points2
rec.array([( 1, 1, 2), ( 3, 4, 5), (10, 20, 30)],
dtype=[('x', 'i1'), ('y', 'i1'), ('z', 'i1')])
What does this give us? Well, instead of subscripting the object points, we can now access x, y, and z as attributes of points2:
>>> points2.x
array([ 1, 3, 10], dtype=int8)
>>> points2.y
array([ 1, 4, 20], dtype=int8)
>>> points2.z
array([ 2, 5, 30], dtype=int8)
Now, we can treat the x, y, and z, as individual arrays and use them as such -- carry out arithmetic operations, transform them, compute statistics, etc.:
# radius ** 2
>>> points2.x ** 2 + points2.y ** 2 + points2.z ** 2
array([ 6, 50, 120], dtype=int8)
>>> points2.x.mean(), points2.x.var()
(4.666666666666667, 14.888888888888891)
More dtype magic -- RGBA values from integers
To drive home the point of accessing an ndarray's data as a different data type, let's look at the following example which is a bit more complex.
Here, we construct an array of three pixels in RGBA format as 16-bit ints:
>>> cyan, magenta, yellow = 0x00ffff01, 0xff00ff01, 0xffff0001
>>> x = np.array([cyan, magenta, yellow], dtype=np.int32)
>>> bytes(x).hex()
'01ffff0001ff00ff0100ffff'
We now change the view to access the red, green, and blue values separately. We also utilize the offset feature of a dtype in order to skip over the alpha values:
>>> dt = np.dtype({
'names': ['b', 'g', 'r'],
'formats': ['u1', 'u1', 'u1'],
'offsets': [1, 2, 3],
'titles': ['Blue pixel', 'Green pixel', 'Red pixel']
})
>>> colors = x.view(dt)
>>> colors
array([(255, 255, 0), (255, 0, 255), ( 0, 255, 255)],
dtype={'names':['b', 'g', 'r'],
'formats':['u1', 'u1', 'u1'],
'offsets':[1, 2, 3],
'titles':['Blue pixel', 'Green pixel', 'Red pixel'],
'itemsize':4})
Voila! We have separated out the red, and the green, and the blue!
Here we defined a format of three one-bit integers (u1) and offsets of [1, 2, 3] (i.e. the bytes with index 1, 2, and 3). Note that we skip over the 0th byte, the alpha value.
We can now access the red, green, and blue values separately:
>>> colors['r']
array([ 0, 255, 255], dtype=uint8)
>>> colors['g']
array([255, 0, 255], dtype=uint8)
>>> colors['b']
array([255, 255, 0], dtype=uint8)
For more about dtypes, see the NumPy documentation.
Of course, we could convert the structured array into a record array and access the RGB values as attributes:
>>> colours = colors.view(np.recarray)
>>> colours.r
array([ 0, 255, 255], dtype=uint8)
>>> colours.g
array([255, 0, 255], dtype=uint8)
>>> colours.b
array([255, 255, 0], dtype=uint8)
A note about the offsets
Note the offset values that were provided. By not providing the 0 offset, we've essentially skipped over the alpha value. Note that since we're working with a little-endian representation, and hence:
- The first byte is the alpha value
- The RGB values are in the reverse order in which we initially specified.
Summary
We've seen different ways of viewing the same data in a NumPy array as different datatypes. We've seen the ability to name and describe the different values. We've also seen ways to skip over data and pick only the ones we're interested in.
There's a lot more that can be done -- for example, change the stride of multidimensional arrays, etc. In some cases, these operations do not involve changing the underlying data, i.e. does not involve copying the data. These type of capabilities make NumPy a powerful tool.
References:
- NumPy Documentation
- Advanced NumPy. By Pauli Virtanen. 2010. [Virtanen is a contributor to NumPy and SciPy and was on the NumPy Steering Council from 2008 to 2021]